These benefits power every real-world use case — whether a roadside vendor scanning QR codes, a large retailer, or a remittance to a family member across states. In August 2025, UPI crossed 20.01 billion transactions in just one month, a landmark moment in India’s digital payments history. This staggering figure isn’t just a statistic; it is a clear indication that what began as a fintech experiment has now become an integral part of everyday life. Behind every tap, scan, and “pay now” prompt lies a massive ecosystem underpinned by data engineering, analytics, real-time processing and trust.
Everyday UPI: From Morning Coffee to Monthly Bills
Imagine a typical morning in any Indian city. You wake up, check your phone, and head towards a nearby coffee shop. You pay for your filter coffee using the UPI app; no swiping a card, no fumbling around for change. Later, you book an auto ride, split the fare with your friend via UPI, pay your electricity bill, order groceries online, and settle the bill at check-out using a QR code all within minutes.
That seamless experience — instant, reliable, and ubiquitous — has become so ingrained that many of us hardly think about what goes on behind the scenes. Yet whether you’re paying ₹10 or ₹10,000, sending money to a friend, paying at a grocery store, or doing a utility bill, every transaction flows through an infrastructure built to scale, react, secure, analyse, and evolve using big data engineering principles.
How does the System Not crash? Enter Data Engineering
At the heart of India’s payment revolution, in terms of reliability, speed, and scale, lies data engineering. The UPI real-time data engineering architecture is responsible for the design, construction, and maintenance of data pipelines and platforms that process millions of events per second. Without robust data engineering, the entire system will buckle under load.
Here’s how it works in simple terms:
- Data ingestion: Every user action (tap, scan, or request) generates metadata (time, device, location on, user ID). These streams of data are ingested via APIs, message brokers, and edge nodes as part of a large-scale real-time data processing
- Real-time processing: The system parses, validates, enriches, and transforms the incoming data. It applies business rules (“Is the account valid? Sufficient balance? Risk check?”) in milliseconds using frameworks like Apache Flink or Spark Streaming, core technologies in big data engineering.
- Routing & orchestration: The transaction is routed to the correct bank or switch, decisions are made about retries or fallback paths, and logs are kept. This layer relies heavily on data orchestration to coordinate workflows across distributed systems.
- Analytics, monitoring & feedback: Continuous monitoring, anomaly detection, fraud scoring, insights, dashboards — all feed back into the system for optimisation and trust, reinforcing modern fintech data engineering
Because the system is built for low latency, high throughput, and fault tolerance, even surges don’t overwhelm it. Data engineering ensures horizontal scale (adding more nodes rather than forcing monolithic architecture), caching, rate limiting, edge decisions, and robust error handling.

UPI as a Global Case Study
What began as a domestic initiative has quickly evolved into a case study in global digital payments. With India processing tens of billions of UPI transactions monthly, the platform’s scalability, interoperability, and inclusivity are drawing attention from policymakers and payment platforms worldwide.
Countries are watching closely, and some are exploring the adoption or adaptation of parts of the same UPI real-time data engineering architecture. The lessons in real-time data processing, security, monitoring, and scale are highly transferable across financial services, lending, insurance and beyond.
What is Data Engineering?
Before we dive further into UPI’s architecture, let’s clarify what data engineering means in this context:
Definition: The practice of designing, building, and maintaining the infrastructure and systems that collect, process, store, and deliver data for analytics and operational use, often at big data engineering scale.
Components: Data ingestion, transformation (ETL/ELT), streaming, batch processing, data storage (data lakes and warehouses), metadata management, schema design, APIs, monitoring, data orchestration, and governance.
Purpose: Make data available reliably, with quality, at scale, low latency, and in a secure manner. Without it, real-time data processing systems like UPI can’t sustain volume or maintain trust.
In modern enterprises, data engineering enables data analytics, machine learning, real-time dashboards, fraud detection, business intelligence, and other advanced applications. It’s the plumbing behind powerful digital experiences and fintech data engineering platforms.
Benefits of Data Engineering
When you build a scalable data engineering into a digital payments platform, the benefits ripple across the entire ecosystem:
- Speed & low latency – Users expect transactions in milliseconds. Data pipelines tuned for performance make that possible.
- Scalability – As transaction volume grows (and UPI crossed 20 billion in a month!), the infrastructure scales without collapsing.
- Reliability & availability – Redundancy, failover, and idempotency ensure zero or minimal downtime.
- Fraud detection & anomalous behaviour – Real‑time risk scoring and AI/ML models flag suspicious transactions instantly.
- Analytics & insight – Transaction trends, merchant behaviour, segmentation, forecasting, and dynamic offers.
- Regulatory & audit compliance – Storing logs and maintaining river- or lake-based archives meet financial audit requirements.
- Security & trust – Encryption, tokenisation, secure protocols, device binding, and monitoring help preserve user trust.
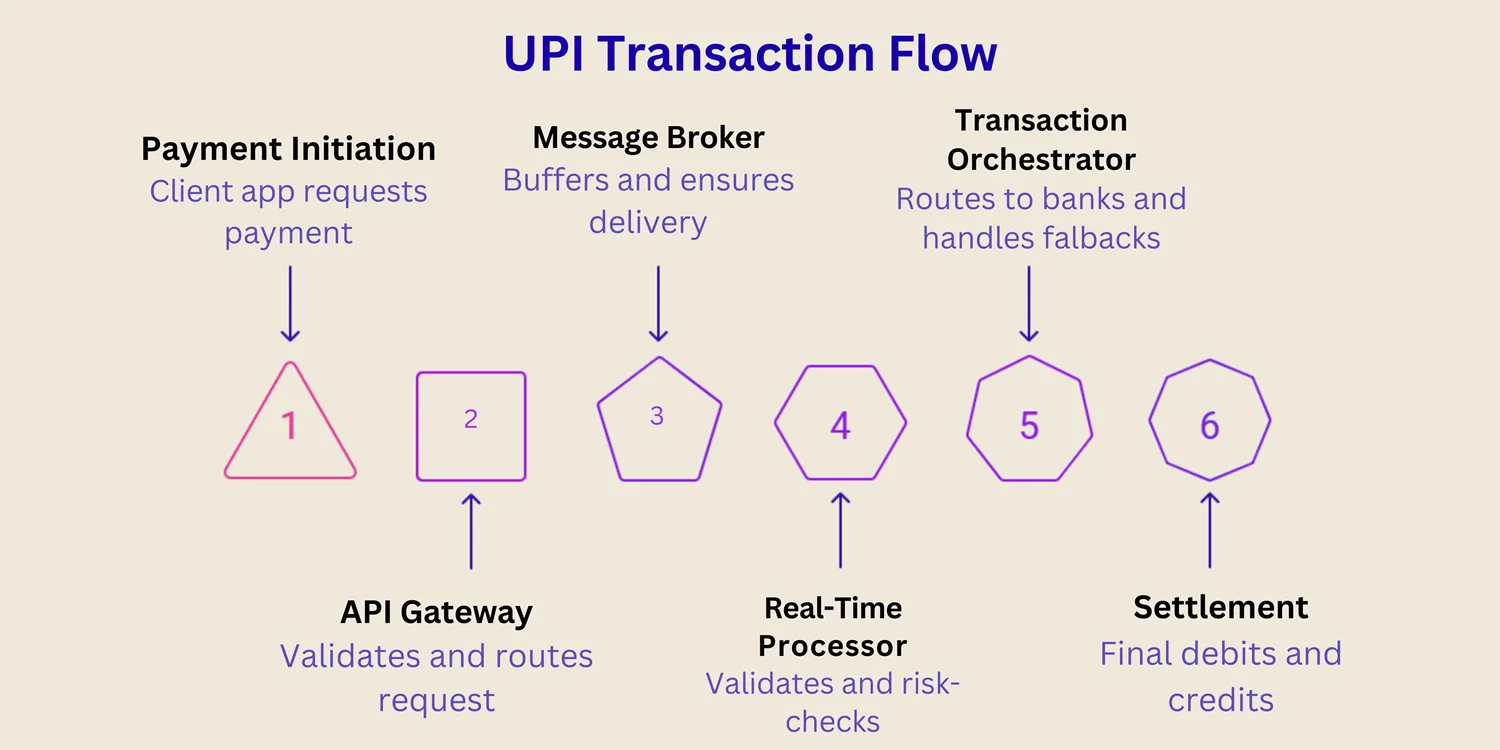
UPI Architecture
| Layer / Component | Role in UPI Ecosystem | How Data Engineering Supports It |
| Client & Apps | Initiates payment requests & collects metadata | Device telemetry, structured payloads, client‑side validation |
| API Gateway / Ingress | Entry point for all requests (apps, banks) | Throttling, routing, input validation, buffering |
| Message Broker / Streaming Layer | Buffers requests, ensures ordering and delivery | Kafka/RabbitMQ, partitioning, replication |
| Real-Time Processor / Rule Engine | Validates, enriches, and risk-checks each transaction | Stream processing frameworks, banking rules, fraud models |
| Transaction Orchestrator / Switch | Routes to issuer/receiver bank switches, handles fallbacks | Distributed decisioning, routing logic, and retries |
| Settlement / Clearing / Ledger | Post final debits/credits, handle reverse flows | Highly consistent storage and reconciliation processes |
| Analytics / BI / Monitoring | Dashboard, trends, alerts, fraud analytics | Data lake, OLAP/OLTP mix, real-time dashboards |
| Archive & Compliance Store | Long‑term retention, audit logs, and regulatory reporting | Data warehouses, cold storage, schema evolution |
Handling Scale and Latency
To support over 20 billion monthly transactions, UPI’s infrastructure must tackle two critical constraints using big data engineering and real-time data processing strategies:
1. Scale
- Peak transactions per second (TPS) can reach multiples of the average load — the architecture must scale horizontally.
- Data volumes vault into petabytes annually.
- Partitioning, sharding, load balancing, geo‑distribution, and edge nodes ensure even load.
- Idempotent design: even if a message is redelivered, effects are consistent.
2. Latency
- From click to confirmation, users expect a response time of under 500 ms (or better).
- Critical data paths are optimised: in‑memory processing, minimal serialisation overhead, protocol tuning.
- Rate limiting and circuit breakers avoid cascading failures.
- Caching and edge decisions reduce the number of round-trip requests.
A well-engineered data pipeline ensures that even under surge conditions (for example, national festivals, sales days), the user experience remains smooth — a hallmark of mature fintech data engineering systems.
Security and Trust
Because money is involved, trust and security are non-negotiable. Several mechanisms and practices ensure UPI remains resilient against fraud, data breaches, and misuse:
- Encryption & tokenisation: Sensitive data (account numbers, device identities) is masked or tokenised so that raw bank details aren’t exposed.
- Two-factor authentication (2FA) and device binding ensure that only authorised users initiate payments.
- Behavioural & anomaly detection models: Patterns, geolocation, historical behaviour feed ML engines to block or flag risky activity.
- Audit trails & logging: Every transaction produces logs, including the initiator, IP address, device, and response codes, enabling disputes or investigations.
- Regulatory compliance: Rules from central bank and financial regulators, encryption standards (TLS, AES), data localisation, periodic audits.
- Incident handling & resilience: Circuit breakers, auto-fallback, and alerting — when a minor failure occurs in a bank or node, the system isolates the issue and triggers alarms.
Trusted for Every Moment, Big or Small
Whether it’s paying for your morning chai or settling the vegetable bill at the local market, UPI has become a quiet yet powerful part of our daily lives. During busy weekdays or lazy weekends, we rely on it to book cabs, pay for food, split bills, and transfer money instantly, with no second thought. It’s fast, it’s easy, and more importantly, it’s trusted. You know the money will reach the right person, and if something goes wrong, there’s always a record to fall back on.
The same trust extends to larger occasions, such as festivals, weddings, and family gatherings. Gifting during Diwali, paying caterers, buying decorations from local stalls, or donating during religious events; UPI is there, working securely in the background. No matter how big the crowd or the celebration, you know your transaction is safe, encrypted, and traceable. In moments of joy or urgency, UPI has earned our confidence because it doesn’t just move money, it moves with integrity.
UPI as Data Infrastructure
UPI is just not a payment system; it is a digital data infrastructure powered by fintech data engineering. As millions of transactions flow daily, they generate valuable data on consumer behaviour, market trends, merchant performance, liquidity flows and more. This layer of insight enables:
- Embedded finance: Using payment data to offer micro‑loans, credit scoring, insurance, or instant financing at the point of sale.
- Merchant analytics & hyperlocal insights: Understand local buying patterns, tailor offers, optimise supply chains.
- Ecosystem growth: Fintechs, banks, startups can plug into this infrastructure to build new services — enabled by APIs, data platforms, SDKs.
- Financial inclusion: Real‑time credit scoring based on transaction behaviour can bring formal credit to underserved populations.
- Macro & policy insight: Regulators and governments can monitor trends, tax flows, and spot anomalies in near real time.
In that sense, the UPI real-time data engineering architecture becomes a backbone for innovation in finance, retail, governance, and beyond.
Frequently Asked Questions
1. Why did UPI become so successful so fast?
Because it combined simplicity (one ID, intuitive apps, QR payments), support from government and banks, interoperability across apps and banks, low cost to merchants, and a robust technical infrastructure built with data pipelines that scaled.
2. What role does real-time analytics play in UPI?
It enables fraud detection, instant decisioning, trend monitoring, anomaly alerts, and continuous feedback into operations. Data engineering makes those analytics pipelines possible.
3. Can UPI architecture be reused for other industries?
Absolutely. The principles of scalable ingestion, real-time processing, orchestration, secure data movement, analytics, and fault tolerance are applicable across various industries, including telecom, IoT, logistics, insurance, healthcare, and more.
4. What happens when a transaction fails?
The system is designed to roll back atomic operations, initiate retries or alternate routing paths, log events, and notify users. The orchestrator and ledger layers handle reconciliation and reversal logic.
5. How does data engineering manage data retention and compliance?
Through tiered storage (hot, warm, cold), schema evolution, archive lakes or warehouses, logs, audit trails, and controlled access. Regulatory requirements may mandate retention periods of 7–10 years in some jurisdictions.
The UPI revolution in India proves that when you pair an inclusive vision with world‑class data engineering, you can reshape how a nation pays, lives, and grows.